
Host Speech Synthesis
Reads the given text aloud on the host, rather than the target.
Library
QUARC Targets/Devices/Peripherals/Host MATLAB Command Line Click to copy the following command line to the clipboard. Then paste it in the MATLAB Command Window: qc_open_library('quarc_library/Devices/Peripherals/Host')
Description

The Host Speech Synthesis block reads the formatted text on the host. It can also output information about the text that is currently being spoken, including the current sentence, word, phoneme or viseme. Visemes are associated with facial expressions, and may be used to animate a face in coordination with the spoken text. Bookmarks are also supported, whereby a notification is received when a bookmark is reached in the spoken text. The text to speak is formatted using a format string, much like the Print block or Stream Formatted Write block.
The Host Speech Synthesis block must be used in connection with a Host Initialize block. The Host name parameter must be set to the identity of the Host Initialize block. The Host Initialize block determines how the speech synthesis on the host will communicate with the real-time code running on the target, which may be remote. Refer to the documentation for the Host Initialize block for details.
The voice used for speaking may be selected using the arrow button to the right of the Voice parameter or a voice may be selected by its attributes of language, voice style, and age. When using attributes to select a voice, the best available voice will be used, with priority given to language first, then voice style, and finally age. Note that the choice of voices on a particular platform depends on the speech recognition software installed or that comes with the operating system, and can be quite restrictive. For example, Windows 7 has built-in speech synthesis but only supports one English voice: Microsoft Anna.
However, for any voice, the volume, speaking rate and pitch may all be adjusted. The volume may vary between 0 and 100%. The rate and pitch range from -10 to 10, with 0 being the normal rate and pitch. Negatives values indicate a slower rate or lower pitch, while higher values configure a higher rate or pitch.
The format string provides the text to be spoken. The format string may contain format specifiers, much like the printf
function in the C language. Each format specifier present in the format string will cause a corresponding input to be created
for the block, unless assignment is suppressed. For a description of the format strings, refer to
Format Strings for Printing. The actual text being spoken may be
output from the block by checking the Show string option.
The length of the final formatted text is limited to the number of code units specified in the Maximum number of code units parameter. A code units typically corresponds to a character, but some characters takes multiple code units to represent them.
It is important, of course, to control when the block speaks the given text. The When to speak parameter provides three different options: use a start input, speak when the input changes or always speak the text. When Use start input is selected, a separate start port is created for the block which controls whether the text is spoken. When a rising edge is seen on the start input, the text is spoken. Otherwise it is not. A straightforward option is to choose Speak if input changes. In this case, the block will speak the text whenever the inputs change. Note that the block could also be placed in a Triggered Subsystem. However, in that case the outputs of the block are less useful because they will only change when the subsystem is triggered.
There is a corresponding option to interrupt the speech. Check the Use stop input option to enable a stop input for interrupting speech. A rising edge on this stop input stops the current speech.
The Output mode controls when the optional outputs of the Host Speech Synthesis block behave. Optional outputs are enabled using the various "Show" checkboxes. Each of the optional outputs corresponds to a particular event during speech synthesis. For maximum flexibility, these output events can be reported as a one-shot pulse that only goes high for one sampling period when the event occurs, or they can hold their last value until the next event occurs. Finally, they can hold their value until reading of the text completes, in which case they go back to zero.
The Show string option allows the result for formatting the text to be output as a string. This output is useful in conjunction with the other optional outputs to extract the word or sentence that is currently being spoken.
The Show bookmark option enables a bookmark output. This output is an unsigned 32-bit integer whose value corresponds to the value of the bookmark when it is encountered in the spoken text. Bookmarks are added to the speech output by placing the following markup in the format string:
<bookmark mark="1">
where the "1" is the bookmark number and may be replaced with any integer greater than or equal to one. Do not use zero for the bookmark number because zero is used at the bookmark output to indicate that no bookmark has been reached.
Other markup may be used in the format string to control speech. In general, if the XML element is empty then it applies to all text spoken thereafter - it is a global setting. If the XML element has textual content, then only that content is modified. For example, to control the volume of the word "whisper" only, in the expression "Let's whisper", add the markup:
Let's <volume level="10">whisper</volume>
where the "10" may be replaced with the desired volume level. Volume levels may vary from 0 to 100 and represent the percentage of full volume.
To control the volume of all text spoken subsequently, add an empty volume tag, such as:
<volume level="50"/>
Use the rate tag to control the speaking rate. To control the absolute speed of speaking, use
the absspeed attribute, such as:
Say this <rate absspeed="8">really fast</rate>
where the "8" may be replaced with the desired rate. Rates may vary from -10 to 10, where 0 denotes the normal speaking rate.
A relative change in speaking rate may also be accomplished using the speed attribute. For example:
Say this <rate speed="-7">slower</rate> than the rest of the sentence.
To control the pitch within text, use the pitch tag. The absolute pitch is set using the
absmiddle attribute, in a similar fashion to the rate tag with the absspeed
attribute. The relative pitch is configured using the middle attribute, akin to the speed
attribute. The valid range of pitches is -10 to 10, just like the rate.
Unlike the previous tags, which may or may not have content, the next two tags must have content. The emph
tag is used to emphasize a particular word or phrase. For example:
That is so <emph>cool</emph>!
Similarly, if have a word or phrase spelled out rather than pronounced as a word or phrase, use the spell
tag. For instance:
Here is how you spell confederation <spell>confederation</spell>
To output a known period of silence, use the silence tag, specifying the number of milliseconds of
silence. This tag must be empty. For example:
There will now be a minute of silence <silence msec="60000"> Thank you for remembering our fallen heroes
Sometimes there are situations where the speech synthesis engine does not pronounce a word or phrase as desired. In such
circumstances, the pronunciation may be specified explicitly using the pron tag. For example:
<pron sym="h eh 1 l ow & w er 1 l d">hello world</pron>
Note that the content of this tag is ignored but is useful for recognizing the pronounced phrase. The value of the
sym attribute is a white-space separated list of phonemes.
The pronunciation of some words varies with the part of speech. For example, the word "record" has a different
pronunciation depending on whether it is a verb or a noun. To help the speech engine differentiate between these
two circumstances, use the partofsp tag. Valid parts of speech are "Unknown", "Noun", "Verb",
"Modifier", "Function", "Interjection". For instance:
Check out this old <partofsp part="noun">record</partofsp>!
Other contexts, such as dates, are specified using the context tag. For example:
<context id="date_mdy">03/04/01</context> should be March fourth, two thousand one.
The valid context identifiers is determined by the currently selected voice.
The Show sentence option enables the optional sentence output. It outputs information about the sentence currently being spoken. See the sentence output for details. Use the String Subset block to extract the sentence from the string output.
Likewise, the Show word and Show phoneme enable the word and phoneme outputs respectively, which provide information about the word and phoneme currently being spoken. Use the String Subset block to extract the word from the string output.
The Show viseme option enables the viseme output, which can be used to coordinate facial expressions with the speech. The Host Speech Synthesis block supports 22 visemes:
| Viseme ID | Description |
|---|---|
|
0 |
The viseme representing silence. |
|
1 |
The viseme representing ae, ax, and ah. |
|
2 |
The viseme representing aa. |
|
3 |
The viseme representing ao. |
|
4 |
The viseme representing ey, eh, and uh. |
|
5 |
The viseme representing er. |
|
6 |
The viseme representing y, iy, ih, and ix. |
|
7 |
The viseme representing w and uw. |
|
8 |
The viseme representing ow. |
|
9 |
The viseme representing aw. |
|
10 |
The viseme representing oy. |
|
11 |
The viseme representing ay. |
|
12 |
The viseme representing h. |
|
13 |
The viseme representing r. |
|
14 |
The viseme representing l. |
|
15 |
The viseme representing s and z. |
|
16 |
The viseme representing sh, ch, jh, and zh. |
|
17 |
The viseme representing th and dh. |
|
18 |
The viseme representing f and v. |
|
19 |
The viseme representing d, t and n. |
|
20 |
The viseme representing k, g and ng. |
|
21 |
The viseme representing p, b and m. |
Finally, speech synthesis can be enabled or disabled for the block using the Enabled option.
Helpful Hints
Terminating Phrases
 The last word of a phrase will appear to be spoken quickly if the phrase is not terminated with a punctuation mark. For example,
the phrase "Shutting down system" will sound like "Shutting down sys" when there is no period at the end of the phrase. Put
a period at the end of the phrase, such as "Shutting down system." to have it pronounce it as "Shutting down system". The
period is not spoken, but adds a brief pause at the end of the speech.
The last word of a phrase will appear to be spoken quickly if the phrase is not terminated with a punctuation mark. For example,
the phrase "Shutting down system" will sound like "Shutting down sys" when there is no period at the end of the phrase. Put
a period at the end of the phrase, such as "Shutting down system." to have it pronounce it as "Shutting down system". The
period is not spoken, but adds a brief pause at the end of the speech.
Mispronounciations
If a word is mispronounced, the easiest way to get it to pronounce the word correctly is to spell the word phonetically.
For example, the word "camera" may be pronounced as "came-er-a" instead of "cam-er-a". To get it to pronounce camera
correctly, just spell it as "cammera" instead.
Installation Requirements
Microsoft Speech Recognition
 Before using the Host Speech Synthesis block, configure the default Microsoft speech synthesis engine that comes with
Windows 7 and above in Control Panel. Failure to do so will cause it to ask for settings when the model is first run.
Before using the Host Speech Synthesis block, configure the default Microsoft speech synthesis engine that comes with
Windows 7 and above in Control Panel. Failure to do so will cause it to ask for settings when the model is first run.
Input Ports
...
Input ports contain the data to be formatted. The number of input ports is determined by the number of format specifiers, such as %lg,
in the specified format string. The %n format specifier does not produce an input port. Instead it causes an output port to be created. All other
valid format specifiers cause corresponding input ports to be created. Variable-sized field widths, precisions and code unit specifiers also cause input
ports to be created in order to specify the field width, precision or maximum number of code units. Inputs corresponding to string or variable dimension
format specifiers may be variable-size signals. See Variable-Size Signals
for more information on variable-size signals.
start
This port is only present if the When to speak parameter is set to Use start input. When a rising edge is seen on this input then the text is spoken. Otherwise it is not.
stop
This port is only present if the Use stop input parameter is checked. When a rising edge is seen on this input then the speech is interrupted.
Output Ports
done
This output goes high for one sampling instant after the text has finished speaking.
...
Subsequent output ports, with the exception of the last two ports, are used for %n specifiers in the format string, which produce the number of code units
processed up to that point in the format string.
string
This output is optional and is only present when the Show string parameter is checked. It contains the result of formatting the text as a string. Hence, it represents the actual spoken text as a string. The sentence and word outputs provide information about the starting and ending positions within this string of the sentence or word being spoken.
bookmark
This output is only present when the Show bookmark option is checked. It outputs a 32-bit unsigned integer containing the bookmark identifier of the last bookmark encountered.
sentence
This output is only present when the Show sentence parameter is checked. It outputs a 2-vector of 32-bit unsigned integers containing the zero-based starting and ending positions within the text of the sentence currently being spoken. The ending position refers to the character immediately following the last character in the sentence. Use the String Subset block to extract the sentence from the string output.
word
This output is only present when the Show word parameter is checked. It outputs a 2-vector of 32-bit unsigned integers containing the zero-based starting and ending positions within the text of the word currently being spoken. The ending position refers to the character immediately following the last character in the word. Use the String Subset block to extract the word from the string output.
phoneme
This output is only present when the Show phoneme option is checked. It outputs a 4-vector of 16-bit unsigned integers containing the phoneme identifier, the duration of the phoneme in milliseconds, a feature flag indicating whether the phoneme is for emphasis or stress, and the phoneme identifier for the next phoneme to be rendered.
viseme
This output is only present when the Show viseme option is checked. It outputs a 4-vector of 16-bit unsigned integers containing the viseme identifier, the duration of the viseme in milliseconds, a feature flag indicating whether the viseme is for emphasis or stress, and the viseme identifier for the next viseme to be rendered.
fields
An int32 value indicating the number of fields from the format string that were written to the stream buffer successfully and fully. This number may be less than the number of fields defined in the format string if the maximum number of code units was reached before all the fields were written to the stream buffer. If an error occurs, then this value indicates the number of fields that could be written successfully, which may assist in locating the source of the error.
error
An int32 value indicating whether any errors occurred. It is zero if no errors occurred and a negative error code otherwise. See Error Codes for the different error codes and their values. Use the Compare to Error block rather than the error code itself to check for specific error codes. To check for errors in general, simply test whether the output is non-zero.
Parameters and Dialog Box
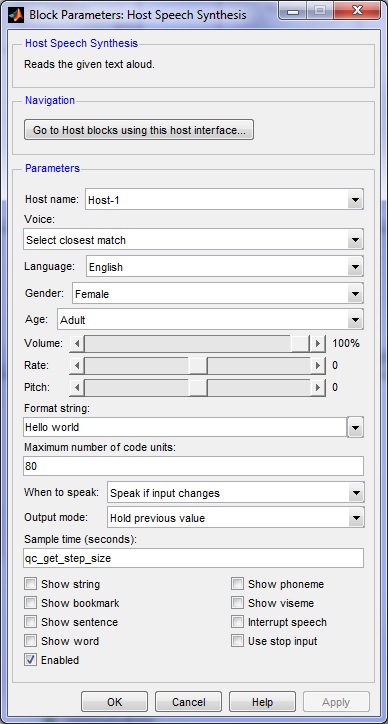
Host name
The identity of the associated Host Initialize block. The Host Speech Synthesis block must be associated with a Host Initialize block.
Voice
The name of the voice to use for speech synthesis. Set to "Select by attributes" to use the Language, Voice style and Age parameters to select the voice instead.
Language
The language to use for speech synthesis. Choose from one of the languages available. If no voice with the specified language is available then another language (likely English) will be used.
Voice style (tunable offline)
The voice style of the speaker to use for speech synthesis.
Age (tunable offline)
The age of the speaker to use for speech synthesis.
Volume (tunable offline)
The volume of speech. Specify a value from 0 to 100 indicating the percentage of full volume. This
parameter only determines the initial volume. The volume may be changed for elements within the text
using the volume tag as described above in the description of the block.
Rate (tunable offline)
The speed of speech. Specify a value from -10 to 10 indicating the speed of speaking. A value of 0 is
the normal speaking rate. This parameter only determines the initial rate. The rate may be changed for elements within the text
using the rate tag as described above in the description of the block.
Pitch (tunable offline)
The speed of speech. Specify a value from -10 to 10 indicating the speed of speaking. A value of 0 is
the normal speaking pitch. This parameter only determines the initial pitch. The pitch may be changed for elements within the text
using the pitch tag as described above in the description of the block.
Format string
The format string used to format the data. Refer to the Format Strings for Printing page for a description of the format string. This parameter is treated as a string literal. It is not evaluated. Hence, do not enclose the format string in quotes unless you wish the quotes to appear in the output.
Maximum number of code units
This parameter restricts the total number of code units in the formatted text. This limit is a hard limit. The total number of code units spoken will never exceed this limit, even if the output for an input port is truncated or all the input ports have not been included in the output.
When to speak
This parameter determines when the text is actually spoken. Enabling speech can be done using a start input or only when the text actually changes, or on every sampling instant for which the block is executed.
Output mode
This parameter determines how the optional outputs are presented. Events may be reported by a one-shot pulse that is only high for one sampling instant, as may remain high until speaking has stopped, or remain high until the next event occurs.
Sample time
The sampling period (in seconds) at which spoken commands are output from the Host Speech Synthesis block. A sample time of 0 indicates that the block will be treated as a continuous time block. A positive sample time indicates that the block is a discrete time block with the given sample time.
A sample time of -1 indicates that the block inherits its sample time. Since this is a source block, only inherent the sample time when it is placed in a conditionally executed subsystem, like a Triggered or Enabled Subsystem, or in a referenced model.
The default sample time is set to qc_get_step_size, which is a QUARC function that returns the fundamental sampling time of the model. Hence, the default sample time is a discrete sample time with the same sampling time as the fixed step size of the model.
Show string
Check this option to enable the string output, which contains the text after formatting that is actually spoken.
Show bookmark
Check this option to enable the bookmark output, which indicates when a bookmark has been reached during speech.
Show sentence
Check this option to enable the sentence output, which indicates the sentence currently being spoken.
Show word
Check this option to enable the word output, which indicates the word currently being spoken.
Show phoneme
Check this option to enable the phoneme output, which indicates the phoneme currently being spoken.
Show viseme
Check this option to enable the viseme output, which allows the speech to be coordinated with animated facial expressions.
Enabled (tunable offline)
Check this option to enable the block. If this option is not checked then the outputs will be set to default values. This checkbox is convenient for disabling the block when use of speech synthesis is not desired.
Targets
|
Target Name |
Compatible* |
Model Referencing |
Comments |
|---|---|---|---|
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
||
|
Yes |
Yes |
Last fully supported in QUARC 2018. |
|
|
Rapid Simulation (RSIM) Target |
Yes |
Yes |
|
|
S-Function Target |
No |
N/A |
Old technology. Use model referencing instead. |
|
Normal simulation |
Yes |
Yes |
See Also
Copyright ©2026 Quanser Inc. This page was generated 2026-05-13. Submit feedback to Quanser about this page.
Link to this page.